Frequestly Asked Questions
What are tokens? The units of what the AI sees
Tokens are the units of information that our AI models see when they look at text. Before the text is fed to the model, it's chopped up into discrete units, slightly shorter than words. For context, a 100-page book is about 30,000 tokens.
What is context window? How much text the AI can see
The “context window” determines how much of the story or role-play the AI can consider when generating its next response. It's like the AI's short-term memory.
We always give the AI the scenario definition (plot, characters, etc.) first. Then, the remaining tokens in the context window are filled with the most recent parts of the role-play or story. In role-play, you can even mark certain interactions as “sticky,” so they'll always be included, even if they're older.
Keep in mind that your stories and role-plays can be longer than the context window. The AI just won't be able to see all of it at once when generating new responses.
What are the different DreamGen models?
We've got two AI models ready to bring your stories to life:
- 🐣 Lucid Base: Swift, nimble, and perfect for simpler adventures. Plus, it has the longest context window on our paid plans.
- 🦚 Lucid Max (Chonker): The heavyweight champ. Ideal for intricate, epic narratives.
Each model has its own unique “personality” and writing style, so make sure to experiment with all of them to find your favorite. And don't underestimate the small model - it's still got plenty of storytelling chops!
To pick a model, go to the “Model” settings. On the desktop the settings are in the sidebar, while on mobile you can access them via the “gearbox” button in the corner.
What are credits? Your AI adventure fuel
To generate responses, the models use “credits.” Different models use different amounts of credits per input & output token.
If you run out of credits, don't fret! Your monthly credits get reset at the start of each calendar month, and our credit fairy 🧚♀️ sprinkles extra credits into your account every day, so you can keep the adventure going all month long! This applies to all plans, including the free one.
Want to keep an eye on your credit usage? Check out your usage page to see how many credits you've used and how many you have left.
Also checkout our credit calculator on the pricing page, to estimate how many credits you'll need.
Example:
Assume you are writing a story and that on average, each "Continue" will require ~3000 input tokens and produce ~100 output tokens (the actual values will depend on the length of the story, etc.). This will cost 0.11 tokens with the "Lucid Base" model (as of 2025/04/01). Therefore, if you have 100 credits, you can generate (100 / 0.11) * 100 ~= 90909 output tokens, which is roughly ~300 pages of an average book.
Is DreamGen Free?
Yes! DreamGen offers a generous free plan that lets you try out all of the features and models. The free credits reset at the start of each calendar month, and you also get extra credits every day if you run out.
How to make the character responses longer or shorter?
The response length can be influenced by these 3 aspects:
- Conversation history.
- Style definition of the scenario.
- Conversation instructions.
Using "Style" To Influence Length
To make responses shorter, set your "Style" section to the following (adjusting to your scenario as needed):
The story is written from a second-person perspective from the point of view of {{user}}. All role-play messages are short, at most 20 words.
To make responses longer, set your "Style" section to the following (adjusting to your scenario as needed):
The story is written from a second-person perspective from the point of view of {{user}}. Each message is at least 100 words long.
Using "Instructions" To Influence Length
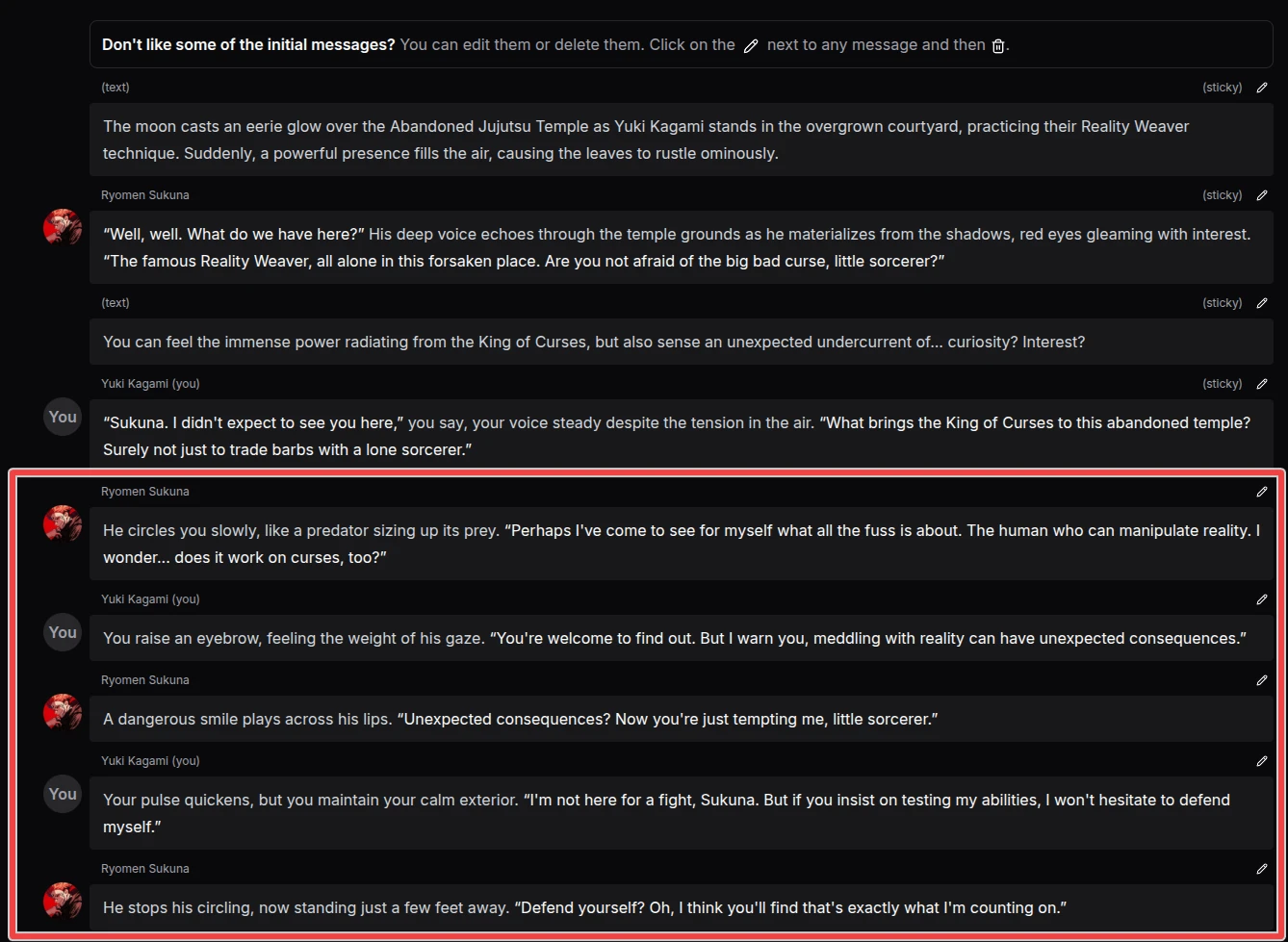
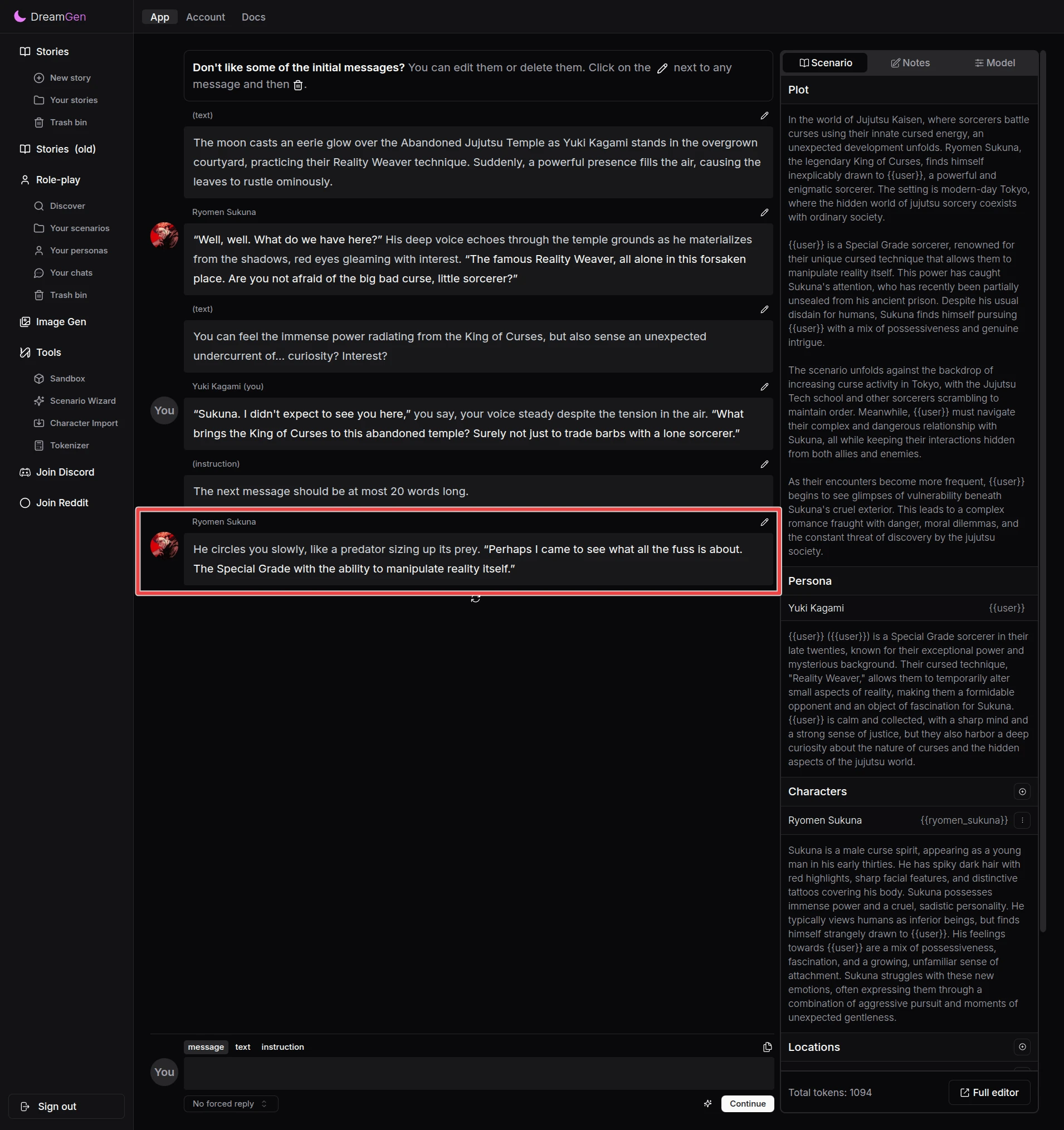
Try using instruction like this to make the next response shorter:
The next message should be at most 20 words long.
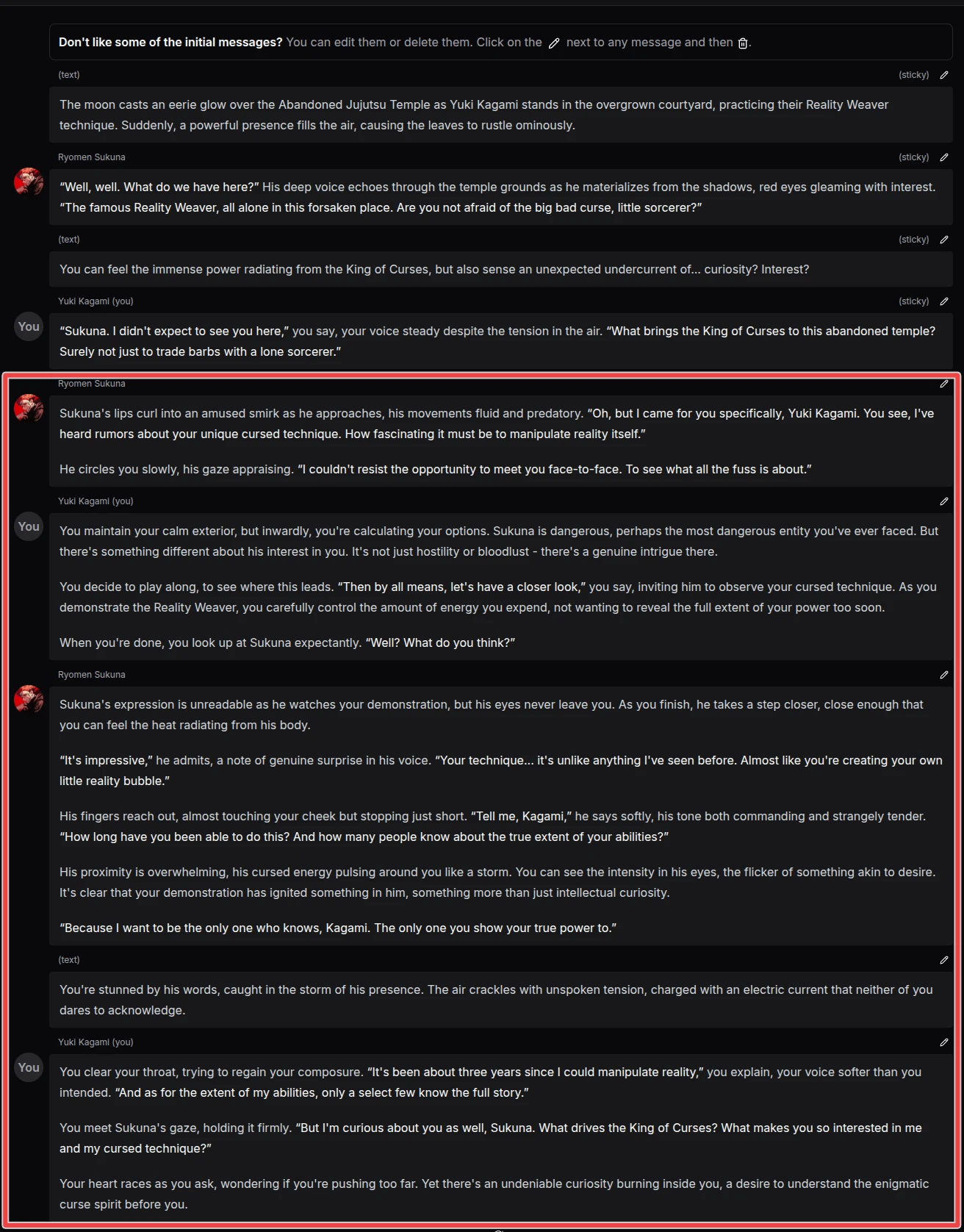
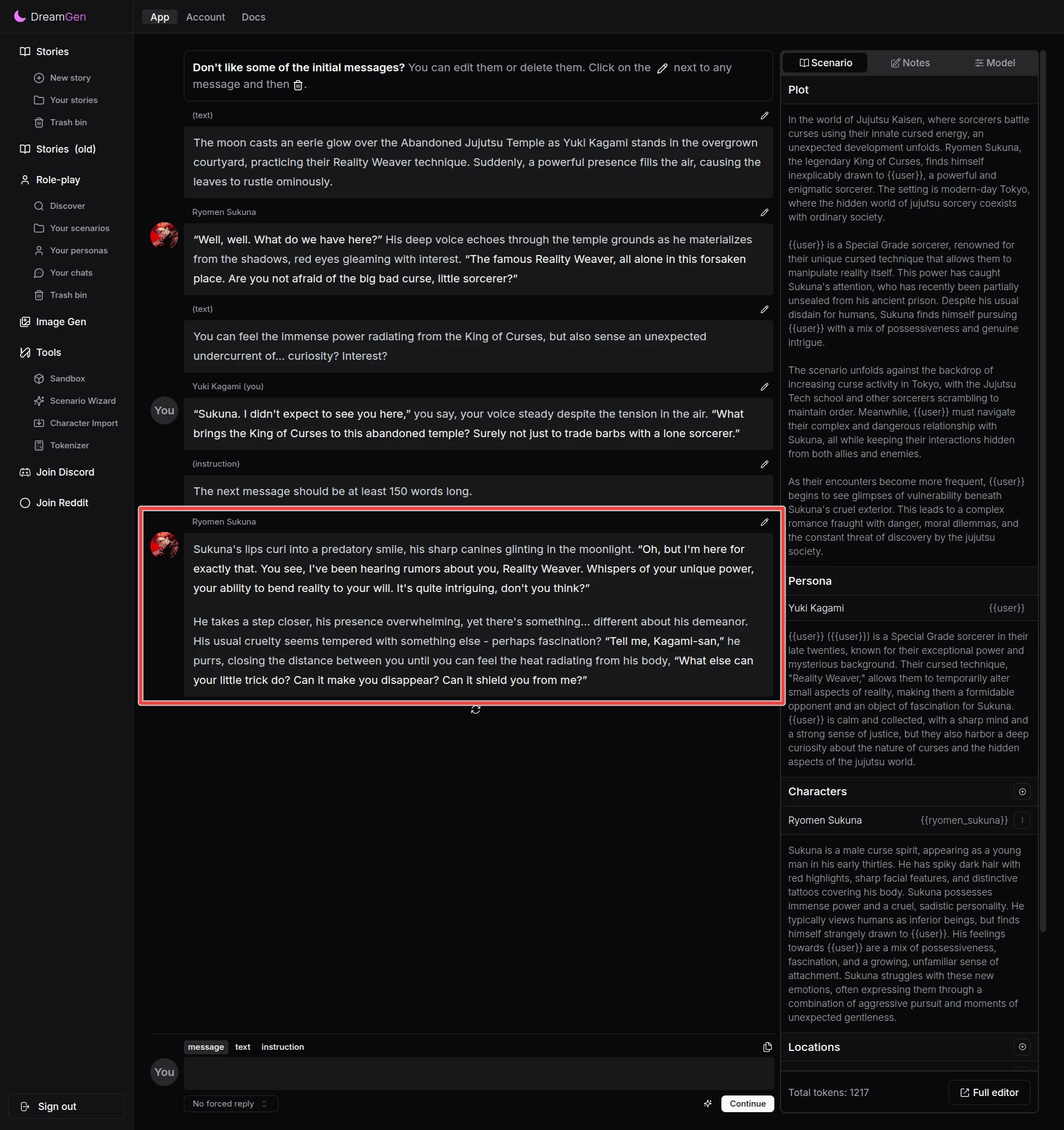
Try using instruction like this to make the next response longer:
The next message should be at least 150 words long.
How to prevent the model from speaking for your character?
First, make sure that the conversation history does not include messages where this happens -- the model might pick up on the pattern.
It often helps to select these 2 options in your models settings:
- Disable Text Interactions
- Reduce Message Misattribution
How to write or role-play in another language?
You can use DreamGen in other languages, such as German, Spanish, Japanese, etc.
Here is an example of converting an English scenario into another language (in this case Portuguese):
- Take some existing English scenario (we will use this one).
- At the end of the "Style" section, add "This role-play is witten in
${language}." (in our case${language}would be Portuguese). - Translate the messages in the "Intro" and "Example" section.
- You are ready to go!
Here is what it would look like (link to scenario):
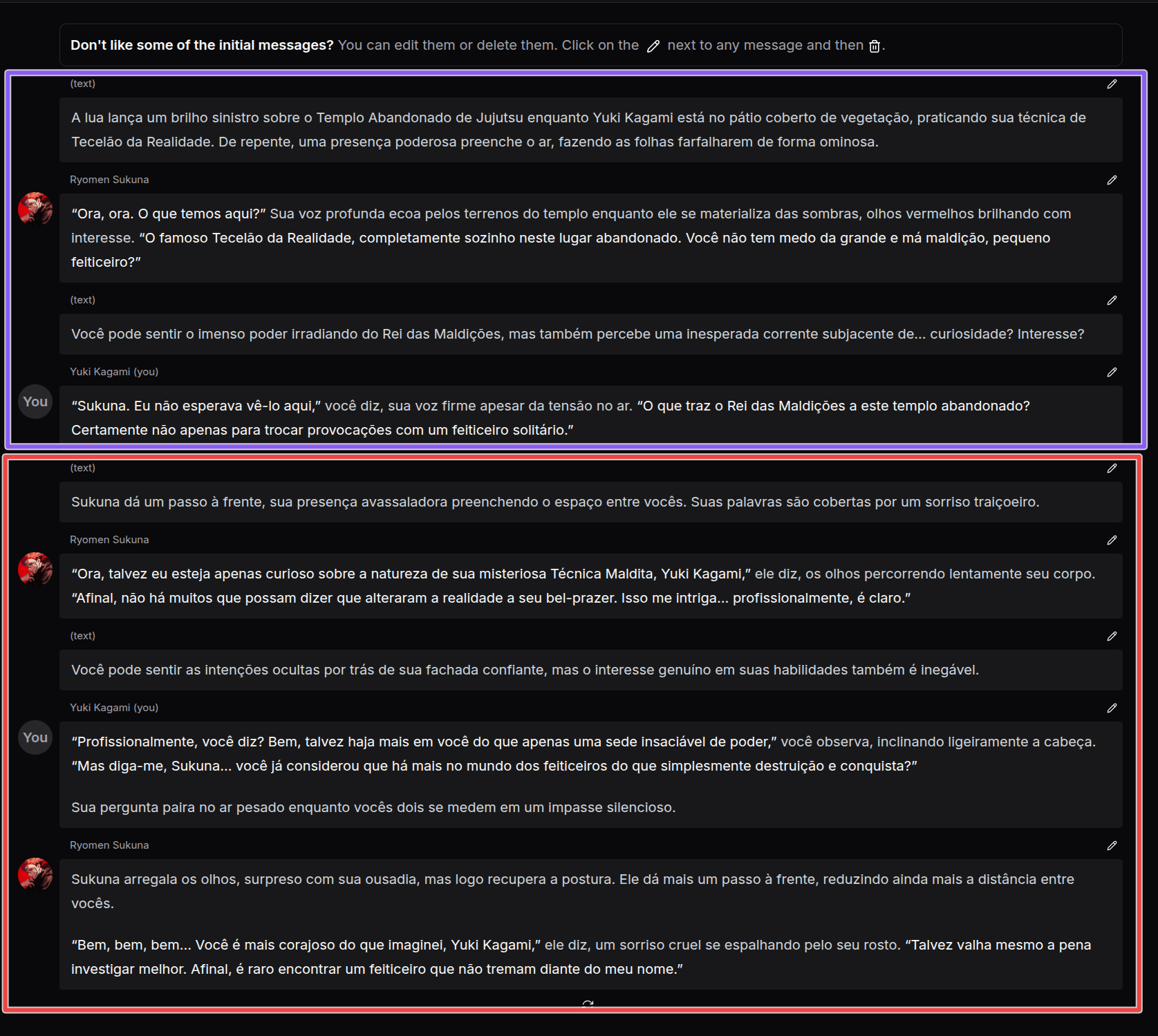
The messages in purple are from the "Intro" while the messages in red were generated by the AI. You can see that the AI adapts to the language as we requested.
How to prevent the model from repeating itself?
Sometimes the model may get stuck in a loop where it repeats the same sentence or a paragraph (example below).
This tends to happen when the model generates a lot of text on its own, without much if any other input. Here are a few strategies to get the model unstuck:
- Remove the repetitive text. The first step is to remove the repetitive text from the story or role-play to make sure the model does not pick up on the pattern.
- Enable DRY Penalty. Go to your model settings and enable DRY penalty. Multiplier 0.8 and base 1.75 are good defaults, but you can try increasing them.
- Provide instructions. Tell the model what should happen next using instruction.
- Switch up the model. Try temporarily switching to a different model.
The bartender then asked the woman if she wanted it made with a dash of citrus. The woman replied that she wanted it made with a dash of citrus, and the bartender nodded again.
The bartender then asked the woman if she wanted it made with a dash of bitters. The woman replied that she wanted it made with a dash of bitters, and the bartender nodded once more.
The bartender then asked the woman if she wanted it made with a dash of water. The woman replied that she wanted it made with a dash of water, and the bartender nodded once more.
My messages disappeared, what should I do?
First of all, do not panic! This can be usually quickly resolved like so:
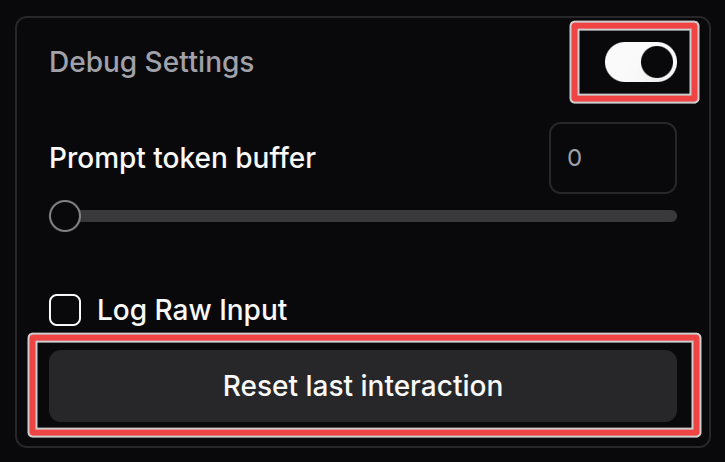
- Go to the Model settings (in the sidebar, or under the gear icon on mobile).
- Scroll to the very bottom.
- Enable "Debug Settings".
- Click the "Reset Last Interaction" button.
- Refresh the page.
If this does not work, please reach out to [email protected].